ch1 - Reliable, Scalable,and Maintainable Applications
Reliability
The system should continue to work correctly (performing the correct function at the desired level of performance) even in the face of adversity (hardware or software faults, and even human error).
Scalability
As the system grows (in data volume, traffic volume, or complexity), there should be reasonable ways of dealing with that growth.
Maintainability
Over time, many different people will work on the system (engineering and operations, both maintaining current behavior and adapting the system to new use cases), and they should all be able to work on it productively.
Reliability
An Reliability System is one that can manage a several different kinds of faults. “continuing to work correctly, even when things go wrong.”
Faultis not the same asFailureAfaultis a component that is deviating from it spec. Afailureis when the whole system stops providing the required service to the user
We generally prefer tolerating faults over preventing faults, there are cases where prevention is better than cure (e.g., because no cure exists).
Hardware Faults
When we think in Hardware Faults come to our minds things like Full RAM Storage or Hard disk crash, etc. One of the most common solution is add Redundancy.
Redundancy is adding more backups at critical sites in our system e. g. Have 2 server for running one in case that the other collapse.
Systems that can tolerate the loss of entire machines, by using software fault-tolerance techniques in preference or in addition to hardware redundancy.
Software Errors
These are types of bugs that occur in software and usually live for a long time before they are discovered.
Things that could help:
- Carefully thinking about assumptions and interactions in the system
- Testing
- Process isolation
- Allowing processes to crash and restart
- measuring
- monitoring
- Analyzing system in production
Human Errors
Humans are unreliable and make mistakes. So here a several ways for avoid the humans errors as we can:
- Design systems that reduce the opportunities for error.
- Decouple the places where people make the most mistakes from the places where they can cause failures. e.g. Create different stages dev, test, prod.
- Test in all levels. From unit test to system integration.
- Quick recovery from a error to minimize the impact of failure.
- Monitoring performance, error, metrics, etc.
Scalability
The Scalability is the capability of a system to manage the increase load.
One system have
Reliabilitynow, that not means that the system have the same in a future.
Describing Load
Load can be described with a few numbers which we call load parameters. These parameters can be:
- Request per second to a web server
- Ratio of read to writes in a database
- Hit rate on a cache These parameters are crucial for understand how system manage the increasing load.
Describing Performance
With the load parameters we can evaluate the system performance in two common ways:
- How the system responds when we increase the
load parametersbut the system resources are the same. - How much we need to increase the system resources when we increase the load parameters to maintain the same performance.
Latency and Response Time Response time is the time it takes to process the request and includes network delays and queuing delays. Latency is the duration that a request is waiting to be handled.
When we see a server report maybe we see things like this:
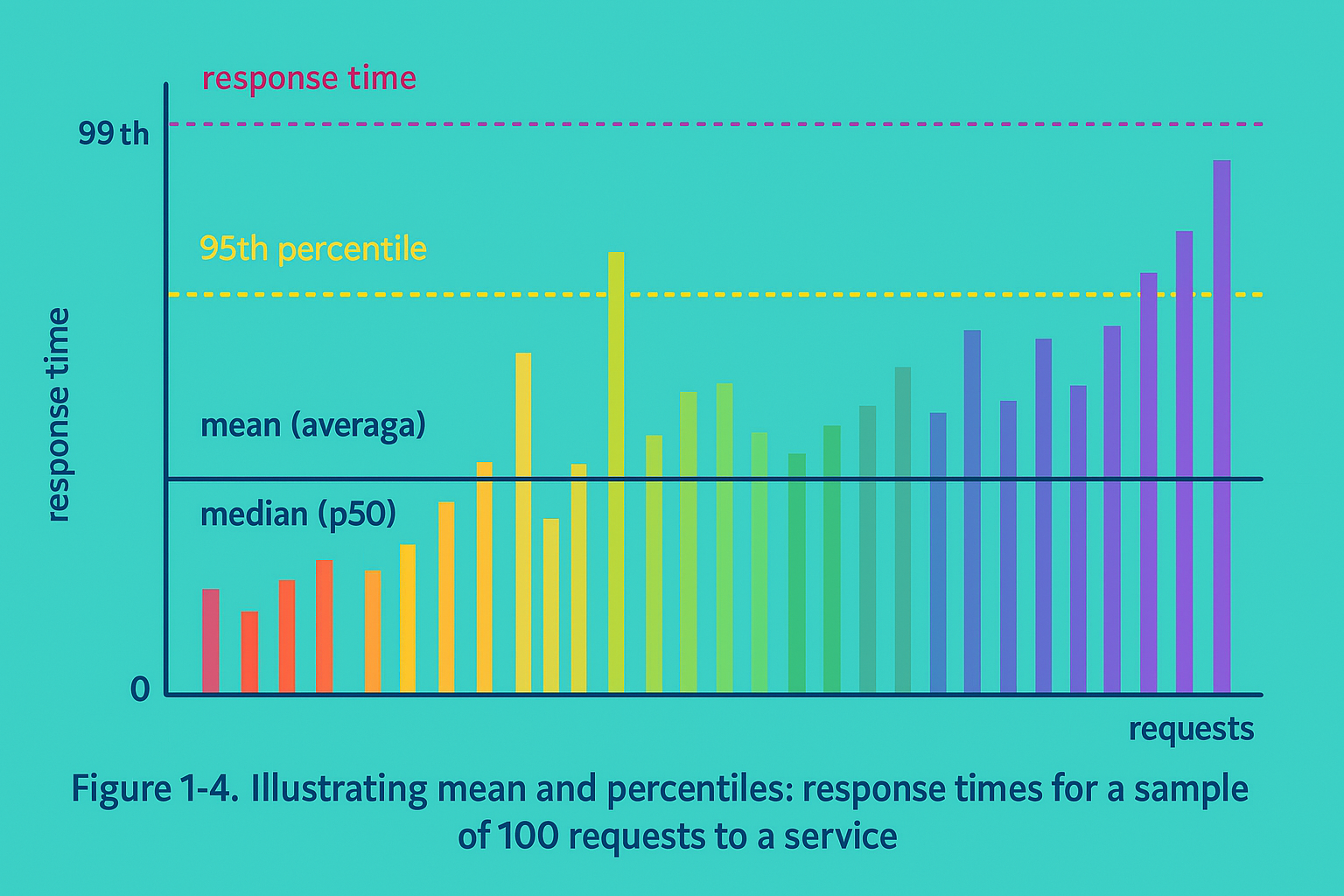
Average response time (given n requests, add up all the values, and divide by n). But sometimes isn’t a good metric because don’t tell you how many users experienced that delays. For example yo have 5 request in ms for 5 users
50, 55, 60, 65, 1000;
Thats means that the average is (50 + 55 + 60 + 65 + 1000) / 5 = 246. So you can think that your system is slow but actually is in one extreme case that is slow.
Using Percentiles
Take a list of response times and sort it from fastest to lowest, the median is the halfway point.
For example If your median response time is 200 ms, that means half your requests return in less than 200 ms, and half your requests take longer than that.
The median percentiles are abbreviated like this: p50 for 50th percentile or 95th, 99th, and 99.9th percentiles are common (abbreviated p95, p99, and p999).
High percentiles of response times like p99 or p999 AKA tail latencies are important because directly they affect users.
Fun fact Amazon find that customers with slowest request are often those who have more data because they have made many purchases. So they are high valuable customers.
Amazon has also observed that a 100 ms increase in response time reduces sales by 1%, and others report that a 1-second slowdown reduces a customer satisfaction metric by 16%.
Approaches for Coping with Load
When you have an Architecture that supports one level of load it is unlikely to support 10 times this load.
Therefore, we have 2 common ways, scaling up (vertical scaling) and scaling out (horizontal scaling).
-
Vertical scalingmeans adding better resources to increase system capacity, for example, using a better and more powerful CPU. Some cloud providers have “elastic” options that automatically increase resources based on demand. -
Horizontal scalingdistributing the load among several smaller machines.
Use a single machine for run our system is more easy but high-end machine become expensive, so in one point some architectures have to use a scaling out.
Maintainability
In most cases, the cost of the software is in the maintainability of the system. Sometimes legacy systems have to be fixed, maintained or upgraded, and in most cases it is painful.
To avoid this, we must keep in mind three principles of software system design.
-
Operability: Facilitates the proper functioning of the system for the operations teams. -
Simplicity: Make the system simple to understand. Eliminate complexity as much as possible. -
Evolvability: Make the system easy to modify in the future. Also known as extensibility, modifiability or plasticity.
Operability: Making Life Easy for Operations
While some aspects of operations can and should be automated, it is still up to humans to set up that automation in the first place and to make sure it’s working correctly. Operations teams are vital to keeping a software system running smoothly.
Good operability means making routine tasks easy, allowing the operations team to focus their efforts on high-value activities.
Simplicity: Managing Complexity
Generally the complexity increase in more bigger software systems and come with problems. The complexity increase the maintainability and the costs. Also increase the change for introduce new error or bugs when when the system is harder for developers to understand and reason about, hidden assumptions, unintended consequences, and unexpected interactions are more easily overlooked.
Evolvability: Making Change Easy
Our system requirements change at various times. Because we change old platforms, business requirements change, we need to introduce changes for legal issues, etc.
So it is important to keep this in mind when we create our systems.
Notes mentioning this note
There are no notes linking to this note.